Import spreadsheets from G Drive
This section covers the technical overview of uploading data into the data platform from a spreadsheet stored in Google drive. For step by step instructions on how to do this and the file types that are supported please refer to the Import spreadsheet from G Drive guide.
The terraform module import_spreadsheet_file_from_g_drive will provision the following resources:
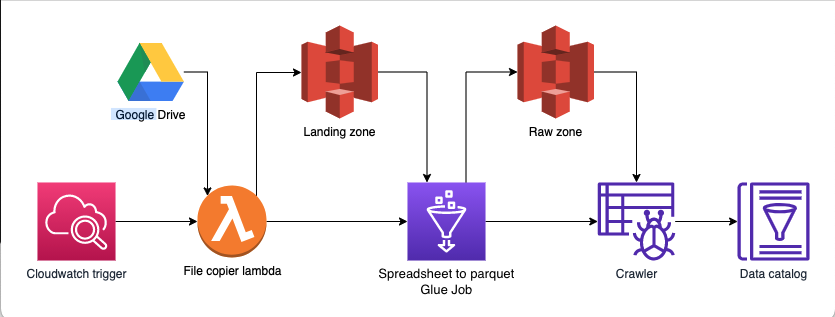
At deployment a single lambda will be deployed per file along side a glue job and crawler provisioned for each worksheet that will be imported.
After deployed a CloudWatch trigger will invoke the copier lambda at 10 am daily.
The lambda will copy the specified file into the S3 landing zone bucket and start all the glue jobs that will import data from the defined workbooks. Spark Web UI is used to monitior and debug the glue jobs. Every 30 seconds, AWS Glue flushes the Spark event logs to an S3 bucket titled Spark UI Bucket.
Upon a successful glue job run a crawler will be run and produce a data catalog for the dataset.